
挖掘业务流程,结合机器学习进行业务预测分析
基于机器学习的流程异常预测行为
目的
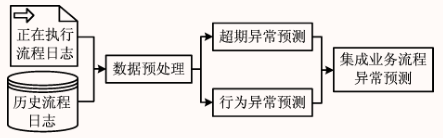
通过挖掘流程执行的日志记录 和活动执行时间信息 ,基于机器学习方法的异常检测方法,实现实时预测业务流程中的超 期 异 常 和 流 程 行 为 异 常。
引言
异常(预期的,完全意外的)
- 流程超期、资源不可用、活动执行失败等和完全意外的异常
现有的流程异常检测方法
- 主动 的 设 置 时 间 检 查点、动态检查,或 被动地基于异常发生后捕捉异常、处理异常的机制
- 主动设置时间检查点的方法有两个弊端,第一个设置点的位置无法精确判断,第二个是系统状态是动态的,受生产环境等诸多条件影响,所以主动i设置会造成很多新的问题
- 被动处理超期异常的方法,失去了对业务流程管理的主动性,从而将导致工作流期望的目标延迟或付出更大的开销。【即失去对于流程预测的主动性】
目前国内外研究动态
基于时间边界的时间异常检测
- 基于时间边界的时间异常检测–Eder
the fifth and sixth document of this paper
首先要明确每个任务节点执行时间的上下边界, 基于这两个时限, 计算起始节点到当前节点的最佳( 最短) 执行时间和最坏( 最长) 执行时间。当流程执行时, 如果当前时间在区间内, 则判断为没有时间异常
- 基于关键路径
the seventh document of this paper
在工作流执行前,会根据模型先找出关键路径, 并在流程执行时检查最佳完成时间与最终时限, 如果最佳完成时间大于最终时限, 则预测为异常
时间统计模型建立
- 执行时间建模方法
the eighth document of this paper
该方法利用历史日志生成涵盖所有活动持续时间直方图来表示当前节点和末端节点之间的剩余执行时间的概率,用于捕获有关工作流执行的时间信息,定义计算工作流执行时间的必要操作
- 综合时间模型和流程步骤分析
the ninth document of this paper
综合运用时间统计模型和通过多个步骤分析方法生成运行时间概率分布、计算异常概率、与阈值比较的方法,提出一种基于运行的异常预测算法来预测工作流中的时间异常,该算法分为即设计时段和运行时段两个阶段,在设计时段,生成该模型所有可能产生的运行轨迹,并计算它们的预计执行时间的概率分布;在运行时段,通过分析计算流程超时的可能性与预设的阈值做比较来判断是否预测为异常
- 结合积极语义模型
the tenth document of this paper
采用积极语义模型来捕捉各种工作流情形下的 语 义 特 征,并 且 检 测 和 处 理 异 常
- 提出受启发与传染病模型的时间延迟传播模型
the eleventh document of this paper
着眼于并行云工作流中的时间延迟,提出受启发与传染病模型的时间延迟传播模型,预测使云工作流中达到一定完成率的最大时间异常数目
离群点检测的算法
孤立森林(Isolation Forest) | 吾辈之人,自当自强不息!
本文
idea
提出一种基于活动执行时间和比例关系的方法,通过学习历史流程执行日志中活动时间信息,根据正在执行的待预测流程的日志及状态,预测其是否为异常流程以及异常的类型。并且,本文提出通过计算活动执行时间之间的比例关系作为流程特征加入机器学习算法,运用机器学习中监督学习的分类器以预测流程是否会发生超期异常(流程执行总时间超过预设最终期限),同时使用非监督学习的离群点检测算法根据历史数据中活动执行时间比例关系判定流程行为异常。结合两种算法的结果对流程异常预测做出进一步的分类和分析。
实现步骤
- 预处理历史和正在执行的流程数据,获得流程中活动执行时间序列以及计算活动执行时间比例关系
- 使用监督学习的分类器,预测并标记超期【流程执行
总时间超过预设最终期限】异常流程为类异常流程 - 用无监督学习检测离群点算法【 活动执行时间之间比例关系(单个活动占总体)为特征值】,找出历史数据中的异常流程并标记为类异常流程
- 通过集成业务流程异常预测方法将待预测流程分为正常流程或者不同种类的异常流程
结构概述
知识补充:弱监督
不完全监督(Incomplete supervision):训练数据中只有一部分数据被给了标签,有一些数据是没有标签的。
不确切监督(Inexact supervision):训练数据只给出了粗粒度标签。可理解为只给了大类的标签,详细属性没有给标签
不精确监督(Inaccurate supervision):给出的标签不总是正确的
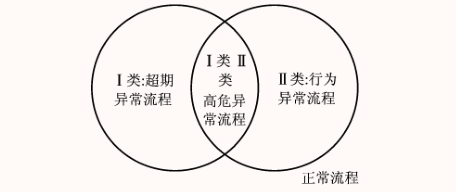
- 第一类通过弱监督学习方法可以标记出大部分的异常流程,但是系统的运行情况很容易受环境资源影响,很多时候由于等待时间过长,被误标为异常流程,但是依旧属于正常流程
- 在实际业务流程中, 活动的执行时间之间并非独立分布, 而是具有隐含的相关关系, 由于多种因素的影响, 造成了活动时间相应的变化。比如工作负荷加倍使得某些活动花费了较长时间, 导致流程总时间较长, 有超期异常的风险。但是从活动执行时间比例关系来看, 流程时间可能被近乎等比例放大, 完全是合情合理的, 并不应该被记为最终期限异常的流程。在活动时间比例上, 正常执行的流程活动时间比例关系是相似的, 而行为异常的流程活动时间比例关系容易出现离群点。因此计算流程中活动时间的比例关系, 并将其作为特征加入算法是有必要的。
解决方案
数据源
数据集
将历史业务流程日志及正在执行流程中的活动执行时间信息作为初始的数据集
TODO
通过目前较为成熟的流程挖掘算法和软件, 如ProM Tools、Disco, 流程模型模拟业务流程获取数据可以简化结构、 缩减活动数量。
数据初始化:
待预测流程的活动数量:n
多条与待预测执行流程路径一致的历史流程数量:q
待预测流程执行时间集:T
其中一条流程的活动执行时间序列:
序列中单个活动的执行时间:
待预测流程执行时间集:
序列k的流程时间:
获得时间比例
对长度为 $n$ 的活动执行时间序列,求出长度为 $n-1$ 的时间比例序,记比例数据集为 $R$
对异常流程进行标记
- 通过历史流程计算出流程执行时间分布,可以给不同活动设定阈值,来标记超期异常流程
- 可以用执行时间拟合建立高斯分布,利用模型参数设立阈值以标记异常(如临界点 $threshold$ ),标记出的异常数据集为【time constrain violation 违规时间约束】
集成业务流程异常预测方法(EnsBPAP)
前提
将待预测流程的活动执行时间序列记为t,将其时间比例序列记为r, 同数据预处理中得到的历史流程的执行时间,比例数据集和标记出的异常数据集 $T$ , $R$ , $tcv$
- 将活动执行时间和比例的训练数据集和测试用例数据传入监督学习的分类算法中, 得到超期异常预测结果
- 将活动时间比例的训练集和测试用例传入无监督学习异常检测算法, 得到行为异常预测结果
- 用两个预测结果访问EnsBPAP分类结果矩阵, 并返回最终的分类结果
EnsBPAP(t,r,T,R,balance_data)伪代码


- 标记超期异常流程
- 标记行为异常【时间比例异常】
- 制定EnsBPAP模型【位运算】
- 将异常流程通过EnsBPAP模型,获得符合模型的综合分类结果
class: 预测测试过程的综合分类结果
超期异常预测
分类器基本模型
- 逻辑回归算法–监督学习
数据存在问题
- 异常点在整个数据集中的数量远小于正常点的数量【样本不均衡问题】,会导致分类器倾向于把预测样本分为多数类。
处理样本不平衡问题—二分类之类别不平衡 | 吾辈之人,自当自强不息!
- 使用过采样和欠采样结合的方法SMOTE + TOMEK algorithm
- 第1步, 将执行时间和比例数据T,R 合并成训练集X, 训练目标为tcv,t,r合并成测试样本x;
- 第2步, 根据balance_data参数选择是否执行SMOTE+Tomek算法均衡训练样本【balance_data平衡训练数据以进行时间约束违规预测】
- 第3步,对每个特征做归一化消除数据量级的影响【归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。】
- 第4步,初始化算法模型,超参数空间,最佳参数
- 第5步,通过若干次迭代随机生成超参数、参考交叉验证法评估当前超参数下的性能、更新最佳超参
- 最后一步,使用最佳超参数拟合算法模型,预测测试样本模型类型,并返回

行为异常检测
目标
- 通过活动执行时间比例找出离群点, 以鉴别待预测流程是否为行为异常的流程。
算法模型
- 孤立森林
- 第1步, 初始化算法模型
- 第2步, 拟合历史数据得到孤立森林模型
- 第3步, 预测测试样本并返回

疑问
- 流程的预设期限如何 在哪 还有 设置的标准没有提到
 wechat
wechat alipay
alipay








