
离群点检测
定义
基本定义
离群点检测(异常检测)是找出其行为不同于预期对象的过程,这种对象称为离群点或异常。
离群点和噪声有区别,噪声是观测变量的随机误差和方差,而离群点的产生机制和其他数据的产生机制就有根本的区别,同一批数据产生方式可能不一样。
全局离群点:通过找到某种合适的偏离度量方式,将离群点检测划为不同的类别;全局离群点是情景离群点的特例,因为考虑整个数据集为一个情境。
情境离群点:又称为条件离群点,即在特定条件下它可能是离群点,但是在其他条件下可能又是合理的点。比如夏天的28℃和冬天的28℃等。
集体离群点:个体数据可能不是离群点,但是这些对象作为整体显著偏移整个数据集就成为了集体离群点。
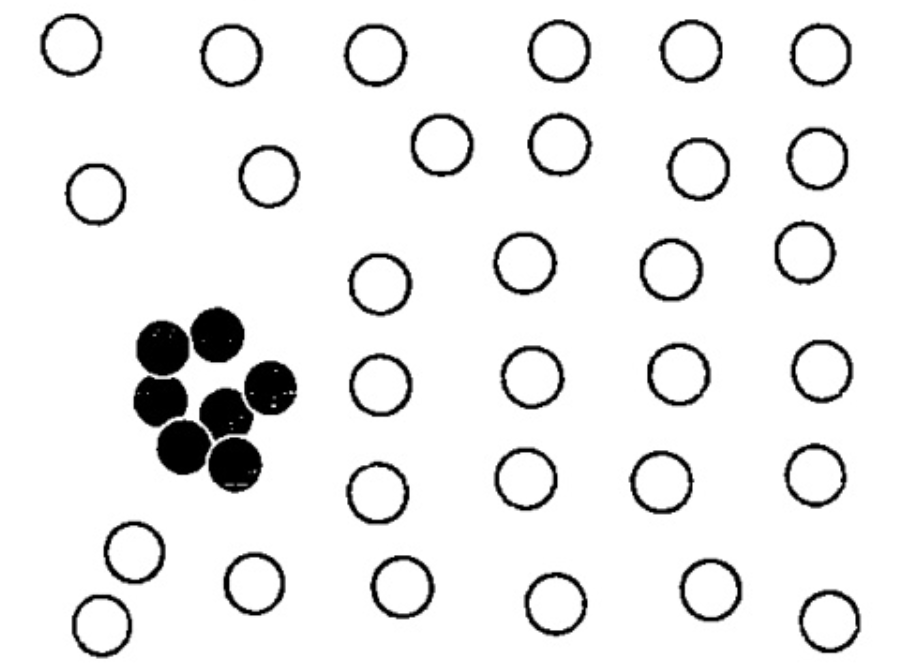
补充学习
有些模型的表现一直不错,建议优先考虑。对于大数据量和高纬度的数据集,Isolation Forest算法的表现比较好。小数据集上,简单算法KNN和MCD的表现不错。
聚类:将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。
簇:把数据划分为不同类别,机器学习给这个类别定义一个新的名字—簇。
离群点检测目前遇到的挑战
- 正常数据和离群点的有效建模本身就是个挑战,数据没有标签,无法分清正常数据还是异常数据;或者缺乏异常数据;
- 离群点检测高度依赖于应用类型使得不可能开发出通用的离群点检测方法,比如针对性的相似性、距离度量机制等;
- 数据质量实际上往往很差,噪声充斥在数据中,影响离群点和正常点之间的差别,缺失的数据也可能“掩盖”住离群点,影响检测到有效性;
- 检测离群点的方法需要可解释性;
离群点检测方法
监督方法
➀训练可识别离群点的分类器
困难: 1 .两个类别(正常和离群)的数据量很不平衡,缺乏足够的离群点样本可能会限制所构建分类器的能力;
2. 许多应用中,捕获尽可能多的离群点(灵敏度和召回率)比把正常对象误当做离群点更重要。
由于与其他样本相比离群点很稀少,所以离群点检测的监督方法必须注意如何训练和如何解释分类率。
➁One-class model,一分类模型
考虑到数据集严重不平衡的问题,构建一个仅描述正常类的分类器,不属于正常类的任何样本都被视为离群点。比如SVM决策边界以外的都可以视为离群点。
无监督方法
正常对象在某种程度上是“聚类”的,正常对象之间具有高度的相似性,但是离群点将远离正常对象的组群。但是遇到前文所述的集体离群点时,正常数据是发散的,而离群点反而是聚类的,这种情形下更适合监督方法进行检测。无监督方法很容易误标记离群点导致许多真实的离群点逃脱检测。
对于传统的聚类方法,有以下几个问题:
- 不属于任何簇的对象可能是噪声,而不是离群点;
- 先找出簇再找出离群点的开销很大(离群点数量远少于正常对象);
半监督方法
当有一些被标记的正常对象时,可以先使用它们,与邻近的无标记对象一起训练一个正常的对象模型,使用这个模型检测离群点;但是由于具有标记的数据只有少部分,意味着仅仅基于少量被标记的离群点而构建的离群点模型不大可能是有效的。
统计方法
假定正常的数据对象由一个统计模型产生,不遵守该模型的数据是离群点。即正常对象出现在该随机模型的高概率区域中,而低概率区域中的对象是离群点
参数方法—壹
基于正态分布的一元离群点检测(仅涉及一个属性或变量的数据)
- 假定数据由某个正态分布产生,由输入来学习正态分布的参数(μ ,σ)(最大似然估计),通过假设检验的方法,一般认定如果某点距离估计的分布均值超过3σ ,就被认为是离群点。下面的文章中提到过利用盒图和四分位数据来划分离群点,其原理类似。
- 另一种离群点检测方法是Grubb检验(最大标准残差检验),对于数据集中的每个对象x,定义z分数(z-score)为:$z=\frac{|x-\bar{x}|}{s}$ , $\bar{x}$是输入数据的均值,s是标准差。
若 $z\geq\frac{N-1}{\sqrt{n}}\sqrt{\frac{t_{a/(2N),N-2}^{2}}{N-2+t_{a/(2N),N-2}^{2}}}$ ,x视为离群点。
其中 $t^{2}\alpha/(2N),N-2$ 是显著水平 $\alpha /(2N)$ 下的 $t-$ 分布的值,N是数据集中的对象数。
参数方法—贰
多元离群点检测
涉及两个或多个属性或变量的数据称为多元数据。核心思想是把多元离群点检测任务转换成一元离群点检测问题。
- 马哈拉诺比斯距离检测多元离群点
对一个多元数据集,设 $\bar{o}$ 为均值向量,对数据集中的对象 $O$ ,从 $O$ 到 $\bar{o}$ 的马哈拉诺比斯距离为: $$M D i s t(o, \bar{o})=(o-\bar{o})^{T} S^{-1}(o-\bar{o})$$ ,S是协方差矩阵。 是一元变量,于是可以对它进行Grubb检验,如果设定为离群点的阈值,则 $o$ 是为离群点。
补充知识:协方差矩阵 | 吾辈之人,自当自强不息!
协方差矩阵:计算样本不同维度之间的协方差
协方差:一般用来刻画两个随机变量的相似程度
补充知识:欧氏距离—–又称欧几里得距离
m维空间中两个点之间的真实距离
例如二维空间的公式:, 为点 与点 之间的欧氏距离
补充知识:马哈拉诺比斯距离
表示数据的协方差距离,它是一种有效的计算两个未知样本集的相似度的方法。
思路:
- 将变量按照主成分进行旋转,消除维度间的相关性
- 对向量和分布进行标准化,让各个维度同为标准正态分布
- 统计量的多元离群点检测
正态分布的假定下, 统计量也可以用来捕获多元离群点,对象 $o$ , 统计量是:
统计量:
是样本测量的一种属性。类似计算样本的平均值。
是$o$在第 $i$ 维上的值,是所有对象在第 $i$ 维上的均值,而n是是维度。如果对象的 统计量很大,则对象是离群点。
- 混合参数分布检测离群
当实际数据很复杂时,假定服从正态分布的话会不太合适,这种情况下假定数据是被混合参数分布产生的。
补充知识:混合分布
在概率与统计中,如果我们有一个包含多个随机变量的随机变量集合,再基于该集合生成一个新的随机变量,则该随机变量的分布称为混合分布(mixture distribution)。
TODO:查阅了混合分布的三个性质没有理解如何判定离群
非参数方法—壹
构造直方图
为了构造一个好的直方图,用户必须指定直方图的类型和其他参数(箱数、等宽or等深)。最简单的方法是,如果该对象落入直方图的一个箱中,则该对象被看做正常的,否则被认为是离群点。也可以使用直方图赋予每个对象一个离群点得分,比如对象的离群点得分为该对象落入的箱的容积的倒数。
非参数方法—贰
补充知识:
向量的内积与外积
对于向量a和向量b:
内积
,内积的几何意义是可以用来表征【信息在头脑中的呈现方式】或计算两个向量之间的夹角,以及在b向量在a向量方向上的投影。
外积
,外积的结果是一个向量,更为熟知的叫法是法向量,该向量垂直于a和b向量构成的平面。
把每个观测对象看作一个周围区域中的高概率密度指示子,一个点上的概率密度依赖于该点到观测对象的距离,使用核函数对样本点对其邻域的影响建模。核函数K()满足以下两个条件:
- 对于所有的 $u$ 值,
一个频繁使用的核函数是标准高斯函数:
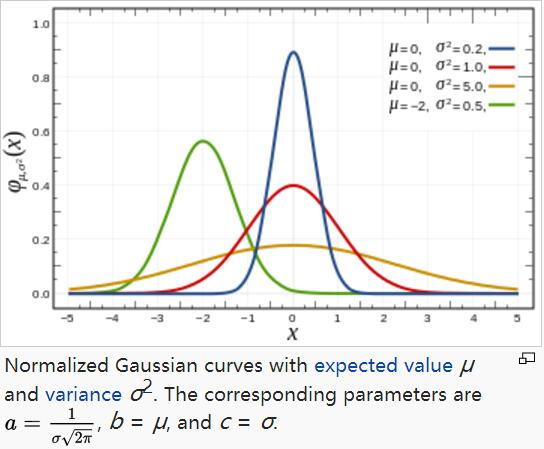
补充知识:高斯函数
一维形式
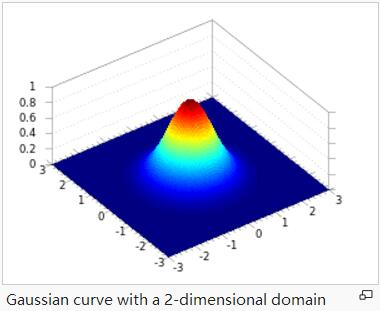
a是曲线尖峰的高度,b是尖峰中心的坐标,c称为标准方差二维高斯核函数常用于高斯模糊Gaussian Blur,在数学领域,主要是用于解决热力方程和扩散方程,以及定义Weiertrass Transform
A是幅值,x。y。是中心点坐标,σx σy是方差,图示如下,A = 1, xo = 0, yo = 0, σx = σy = 1
设 是随机变量 $f$ 的独立同分布样本,那么概率密度函数的核函数近似为:
,K()是核函数,h是带宽,充当光滑参数
对于对象 $o$ , 给出该对象被随机过程中产生的估计概率。如果 过小,$o$ 可能是离群点。
基于邻近性的方法
假定一个对象是离群点,如果在特征空间中的最近邻也远离它,即该对象与它的最近邻之间的邻近性显著地偏离数据集中其他对象与它们的近邻之间的邻近性。
基于邻近性的方法的有效性高度依赖与所使用的邻近性度量,主要有基于距离和基于密度的离群点检测方法。
通俗理解,离群点与近邻点的近邻距离明显大于其它对象与其的近邻的距离。即离群点周边环境明显和其它对象不一样。
基于距离的离群点检测
对象给定半径的邻域,如果它的邻域内没有足够多的其他点,则该点被认为是离群点。
r是距离阈值, 是分数阈值,对象 $o$ 如果满足上面的式子则是一个 离群点。
基于密度的离群点检测
基于距离的检测方法从全局考虑数据集,所找到的离群点都是全局离群点,但实际上数据结构更复杂,对象可能关于其局部邻域,而不是整个数据分布而视为离群点。
基于密度的离群点检测方法基本假定为:非离群点对象周围的密度与其邻域周围的密度类似,而离群点对象周围的密度显著不同于其邻域周围的密度。
D为数据集, 是对象o第k个近邻的对象之间的距离, 是所有在 之内的对象集。可以使用 中的对象到o的平均距离作为局部密度的度量,但是为了避免比如有非常近的近邻使得距离度量统计产生波动,需要加上光滑效果:
$reachdist$
k是用户指定参数,控制光滑效果。对象o的局部密度为:
o的局部离群点因子为:
局部离群点因子是o的可达密度与o的k-最近邻可达密度之比的平均值。对象o的局部可达密度越低,并且o的k-最近邻局部可达密度越高,LOF值越高。
LOF 的思想:
通过比较每个点 p 和其邻域点的密度来判断该点是否为异常点,如果点 p 的密度越低,越可能被认定是异常点。至于这个密度,是通过点之间的距离来计算的,点之间距离越远,密度越低,距离越近,密度越高,而且这里的密度不是基于全局数据,而是基于局部数据。
基于聚类的方法
假定正常数据对象属于大的、稠密的簇、而离群点属于小或稀疏的簇,或者不属于任何簇。直截了当的采用聚类方法用于离群点检测开销会很大,不能很好地扩展到大数据集上。
- 将离群点检测为不属于任何簇的对象
- 最近簇距离的离群点检测
假设o到最近的簇中心为 ,则o与 之间的距离为 , 与指派到 这个簇中的对象之间的平均距离为 ,比率 度量 与平均值的差异程度。
- 识别小簇或稀疏簇
先是找出数据集中的簇,并把它们按照大小降序排列,假定大部分数据点都不是离群点。它使用一个参数 区别大小簇。任何至少包含数据集中 数据点的簇都被视为大簇,其余为小簇。然后对每个数据点赋予基于簇的局部离群点因子(CBLOF)。对于属于大簇的点,它的CBLOF是簇的大小与该点与簇的相似性的乘积。对于小簇的点,其CBLOF用小簇的大小和该点与最近的大簇的相似性乘积计算。
CBLOF代表点属于簇的概率,值越大,点与簇越相似。远离任何大簇的小簇被看作离群点组成,并且具有最低CBLOF值的点怀疑为离群点。
总结
- LOF类的算法适用于局部区域空间问题,对于完整区域空间,KNN和Iforest更好。
- KNN每次运行需要遍历所有数据,所以效率比较低,如果效率要求比较高,用聚类方法更好。
- 传统机器学习算法中Iforest、KNN和OCSVM表现较好,基于深度学习的算法准确率在论文中更好!
- 对于不同种类的数据,没有哪一种算法是最好的,HBOS算法在某些数据集上的表现非常好,且运算速度很快。
- 当数据特征数很多时,如400个特征,只有KNN表现还不错,Iforest表现也不好,因为特征选取的随机性,可能无法覆盖足够多的特征(不绝对)。
- ABOD综合效果最差,尽量不要用。
 wechat
wechat alipay
alipay








