
孤立森林(Isolation Forest)
理解

假设我们用一个随机超平面来切割(split)数据空间(data space), 切一次可以生成两个子空间(想象拿刀切蛋糕一分为二)。
之后我们再继续用一个随机超平面来切割每个子空间,循环下去,直到每子空间里面只有一个数据点为止。
满足的条件
- 数据本身不可再分割
- 二叉树达到限定的最大深度
直观上来讲,我们可以发现那些密度很高的簇是可以被切很多次才会停止切割,但是那些密度很低的点很容易很早的就停到一个子空间里了。
异常检测原理的理解:由于异常值的数量较少且与大部分样本的疏离性,因此,异常值会被更早的孤立出来,也即异常值会距离iTree的根节点更近,而正常值则会距离根节点有更远的距离。
应用
孤立森林算法主要针对的是连续型结构化数据中的异常点。
理论前提
- 异常数据占总样本量的比例很小
- 异常点的特征值与正常点的差异很大
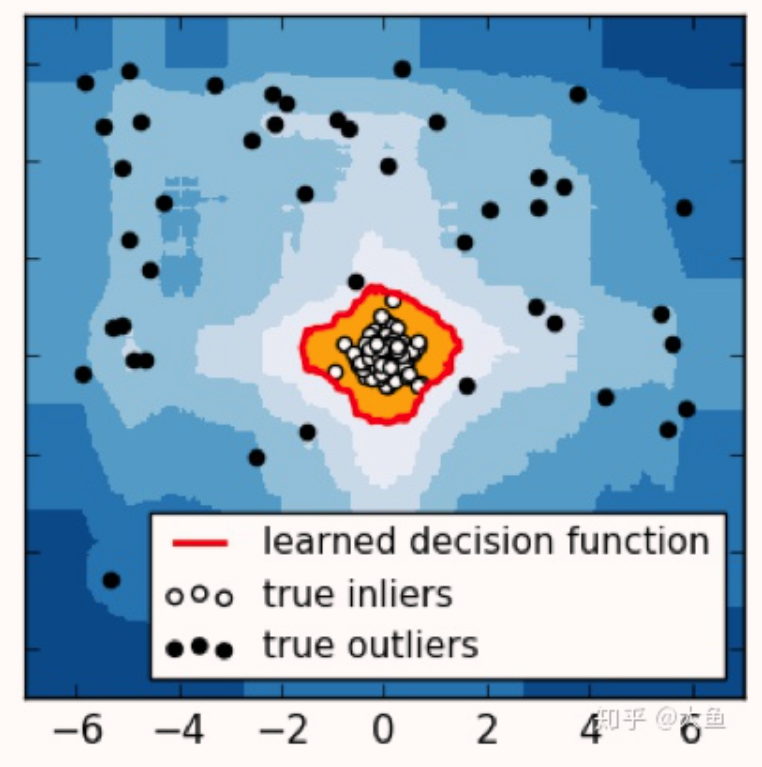
上图中,中心的白色空心点为正常点,即处于高密度群体中。四周的黑色实心点为异常点,散落在高密度区域以外的空间。
场景
孤立森林算法是基于 Ensemble 的异常检测方法,因此具有线性的时间复杂度。且精准度较高,在处理大数据时速度快,所以目前在工业界的应用范围比较广。常见的场景包括:网络安全中的攻击检测、金融交易欺诈检测、疾病侦测、噪声数据过滤(数据清洗)等。
知识补充集成学习算法 (Ensemble Learning)
统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。
孤立森林的创新点
- Partial models:在训练过程中,每棵孤立树都是随机选取部分样本
- No distance or density measures:不同于 KMeans、DBSCAN 等算法,孤立森林不需要计算有关距离、密度的指标,可大幅度提升速度,减小系统开销
- Linear time complexity:因为基于 ensemble,所以有线性时间复杂度。通常树的数量越多,算法越稳定
- Handle extremely large data size:由于每棵树都是独立生成的,因此可部署在大规模分布式系统上来加速运算
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 吾辈之人,自当自强不息!!
 wechat
wechat alipay
alipay
相关推荐






评论


