
注意力机制
注意力机制到底是什么——基于常识的基本结构介绍 - 知乎
(96 封私信 / 80 条消息) 「注意力机制」是什么意思? - 知乎
大话注意力机制(Attention Mechanism) - 雪饼的个人空间 - OSCHINA - 中文开源技术交流社区
attention机制中的query,key,value的概念解释 - 知乎
注意力机制
注意力机制(Attention Mechanism)是人们在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出数据的贡献大小。
目前,注意力机制已经成为深度学习领域,尤其是自然语言处理领域,应用最广泛的“组件”之一。这两年曝光度极高的BERT、GPT、Transformer等等模型或结构,都采用了注意力机制。
理解
来自于认知工程领域提出的,类似人对于信息采集的机制—特征工程。
人身上的注意力机制
去超市购物,和朋友去购物,作为提东西的工具人,不仅要体力跟的上,那么我们还需要的是跟的上朋友的步伐,人山人海中要跟上步伐确实比较困难,当我们用眼睛去一个一个寻找,把路人的信息特征衣服,脸,发色,发型~都传入到脑海中一个一个比对寻找朋友的时候,这时候不仅效率极其低而且大脑表示也遭不住,那么我们只需要记到部分明显特征发型身高等,然后扩大视野,这样效率会明显提高。
像这种情形,**有选择的处理信号**,包括人类很多生物在处理外界信号时的策略,这种处理机制就是注意力机制。
特征工程——模型外部的注意力机制
严格来说,「注意力机制」更像是一种方法论。没有严格的数学定义,而是根据具体任务目标,对关注的方向和加权模型进行调整。
简单的理解就是,在神经网络的隐藏层,增加「注意力机制」的加权。
使不符合注意力模型的内容弱化或者遗忘。
“key-query-value”理论
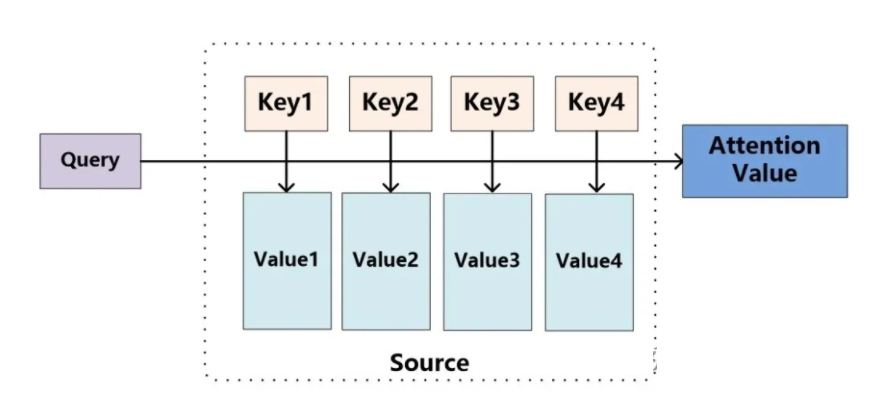
将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
$Attention( Q u e r y , Source ) = \sum _ { i = 1 } ^ { L _ { x } }Similarity(Query,Key_{i})*Value_{i}$
个人理解
可以把attention机制看作一种软寻址:Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,**取出内容的重要性根据Query和Key的相似性来决定**,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。
Attention机制的具体计算过程:
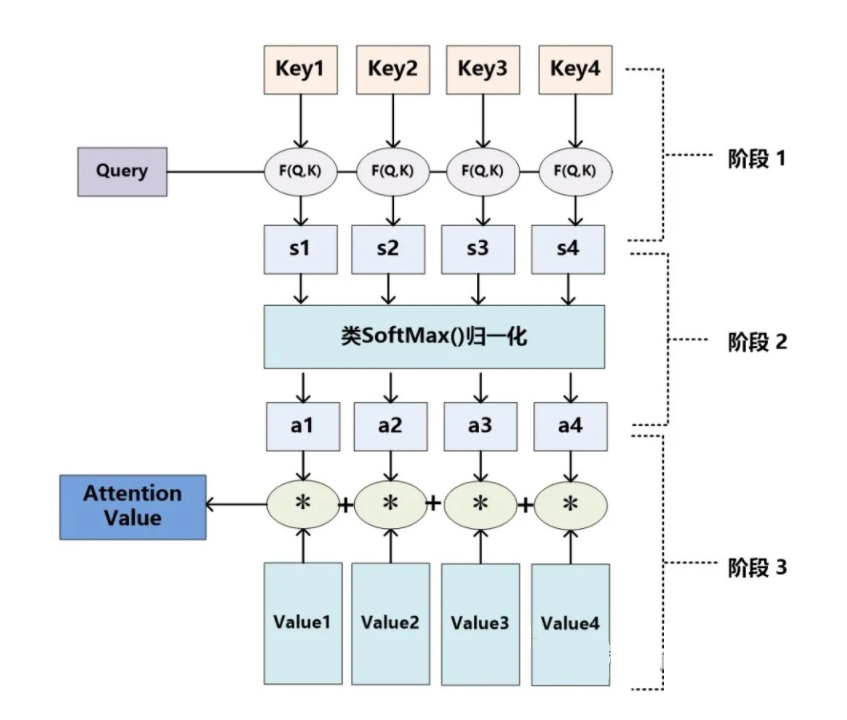
- 根据Query和Key计算两者的相似性或者相关性【学习】
- 对第一阶段的原始分值进行归一化处理【获取权重系数】
- 根据权重系数对Value进行加权求和
知识补充
点乘又叫向量的内积、数量积,是一个向量和它在另一个向量上的投影的长度的乘积;是标量。 点乘反映着两个向量的“相似度”,两个向量越“相似”,它们的点乘越大。
向量叉乘求的是垂直于这两个向量
Cosine相似性,求余弦
多层感知器(Multilayer Perceptron,缩写MLP)一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题
第一阶段中根据Query和Key求相似度目前常见的方法包括:求两者的向量点积、求两者的向量 Cosine相似性或者通过再引入额外的
神经网络来求值如下:
点积:
$Similarity(Query,Key_{i})=Query*Key_{i}$
Cosine相似性:
$Similarity(Query,Key_{i})=\frac { QueryKey_{i} } { ||Query||||Key_{i}||}$
MLP网络:
$Similarity(Query,Key_{i})=MLP(Query*Key_{i}$
第二阶段引入类似SoftMax的计算方式对第一阶段的相似度得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。
$a_{i}=Softmax(Sim_{i})= \frac{e^{Sim_{i}}}{ \textstyle \sum_{j=1}^{L_{x}}e^{Sim_{j}} }$
最后一阶段是加权求和求Attention数值:
$Attention(Query,Source)={\textstyle \sum_{i=1}^{L_{x}}a_{i}\cdot Value_{i}}$
深度学习领域的注意力机制
注意力机制的思想和基本框架
一些学者尝试让模型自己学习如何分配自己的注意力,即为输入信号加权。他们用注意力机制的直接目的,就是为输入的各个维度打分,然后按照得分对特征加权,以突出重要特征对下游模型或模块的影响。这也是注意力机制的基本思想。
一般会采用”key-query-value”理论来描述注意力机制的机理。
 wechat
wechat alipay
alipay








