
基于注意力机制的神经网络业务过程预测分析
摘要
提出了一种具有注意力机制的神经网络,它是使用公开的事件日志(如BPI Challenge 2013)进行训练。
同时使用n-gram模型对比结果和LSTM(长-短期记忆结构的神经网络)对比训练时间。
简介
提到使用以前较小的数据进行与之前的研究进行对比,同时也使用到了较大过程的日志进行评估。
本文的亮点,作者首次提出结合基于自我关注的transformer模型【NLP中常用】进行流程预测。
Transformer:
详解Transformer (Attention Is All You Need) - 知乎
李宏毅-Attention,Self-Attention,Transformer - 知乎
Attention is All You Need
堪比当年的LSTM,Transformer引燃机器学习圈:它是万能的|LSTM|机器学习_新浪科技_新浪网
残差网络
残差网络是为了解决深度神经网络(DNN)隐藏层过多时的网络退化问题而提出。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和然后急剧退化,而且这个退化不是由于过拟合引起的。
深度残差网络 | 机器之心
准备
Attention
self-attention
Attention机制与Self-Attention机制的区别_At_a_lost的博客-CSDN博客_attention和self attention的区别
Transformer
Transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。
为了解决这个问题,论文中在编码词向量时引入了位置编码(Position Embedding)的特征。—自己设计编码规则前馈神经网络也经常称为多层感知器(Multi-Layer Perceptron,MLP)
事件日志
简述日志结构
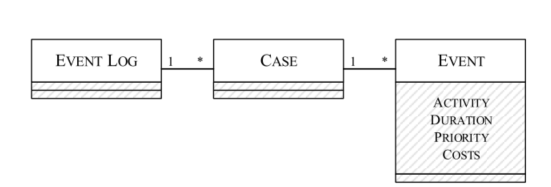
一个事件日志由多个案例组成,但一个案例总是分配给一个事件日志。案件与事件的关系也是如此;事件的典型属性是活动、持续时间、优先级或成本。
事件日志与事件案例:一对多
事件案例与事件:一对多
Attention
这块需要提前学习Transformer
- 通常,序列中的每个位置可以关注序列中的任何其他位置。作者提到为了不让Softmax函数计算时不考虑位置特征,将当前事件之后的位置的值设置为无穷大【忽略位置特征】
- 我的理解是位置特征无法通过分类来实现,这也是Transformer无法捕获序列顺序的原因
- 这里为了梯度的稳定,Transformer使用了score归一化,即除以 $\sqrt{d_{k}}$
**知识补充**:softmax
一文详解Softmax函数 - 知乎
多分类、求大
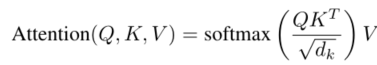
$W _ { i } ^ { Q } , W _ { i } ^ { K } , W _ { i } ^ { V } \in R^{d_{model}*d_{k}}$ , $W^{O}\in R^{hd_{k}*d_{model}}$ 【 $d_{model}$ 表示嵌入的长度(可以理解为词嵌入)】
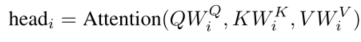
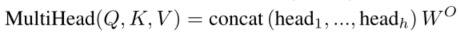
通过学习线性变换将Q向量、K向量和V向量投影到h个不同的子空间中,在每个子空间上并行计算Attention值。结果被连接并投射到特征空间,使得模型能够联合处理来自不同位置的不同表示子空间的特征。
相关
- 2016年之前主要是使用MMs(生成模型)和聚类算法(KNN或k-means)相结合;剩下的就是一些类似MMs,例如,基于贝叶斯概念的概率有限自动机(概率模型),它使用期望的极大似然估计。 数据来源2012,2013公开的BPI比赛。
- 2016至今,几乎都是长短期记忆结构(LSTM)然后与其它模型相结合的方法来预测,比如结合词嵌入的神经网络,使用一个热编码转换事件特征,并将其与生成的时间特征连接到单个特征向量。数据来源2012,2013公开的BPI比赛
- 另一种方法将事件预测视为经典的多类分类问题,并使用堆叠的自动编码器提取特征,然后使用深度前馈网络对特征进行分类。然而,这种方法只适用于简单的数据集,因为不同表示的数量随着唯一事件类的数量呈多项式增长。
知识补充 独热编码
数据预处理:独热编码(One-Hot Encoding)和 LabelEncoder标签编码 - 理想几岁 - 博客园
知识补充 多项式增长
也就是对于变量n,5n^2+2n+1这种就叫做多项式。
数据集
本实验数据集:
- BPI Challenge 2013
- 一家德国软件公司提供的额外数据集。后一个数据集的事件日志包括律师、会计师和审计员使用一种特殊软件工具进行财务核算、管理付款交易和编制年度财务报表的情况。
数据集由大约2.08亿个事件组成,由会话id标识,该会话id指示它们所属的情况、事件类型和时间戳。每个用户交互(通常是点击按钮)都被视为一个事件,一个案例从应用程序启动一直持续到关闭。
难点:
作者通过流程挖掘,许多独特的事件类增加了预测的难度。在较小的数据集中,大多数情况下都非常短。大约四分之一的病例由五个或更少的事件组成,只有百分之一的流程长度为500或更多。
同时数据集中大部分数据为重复的,数据类型不均匀,最常见的五个事件类型几乎占了整个数据集的一半。
建模方法
模型是在tensorflow上实现的,使用tf.data-API作为输入管道,tf.keras-API构建我们的模型。【不懂,反正tensorflow上的组件哇】
数据预处理
- 整理事件类型,并用整数标记
- 将一个流程的所有事件放到一个张量(tensor,多维数组,能够创造更高维度的矩阵、向量。)
- 为每个流程添加一个结束标记,并且通过左移一个位置来生成训练标签【没懂为啥要左移生成标签,但是目的是为了生成训练标签,感觉是通过监控位置标签判断是否为训练数据集】
- 在上一部分中提到数据集长短不一,作者提出通过按照长度将流程分到不同区域中。这里为了确保每个区域中的流程相似,就没有设置固定的长度,而是通过制定上限来控制长度。
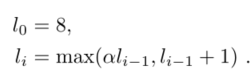
$l_{1}<9$
模型
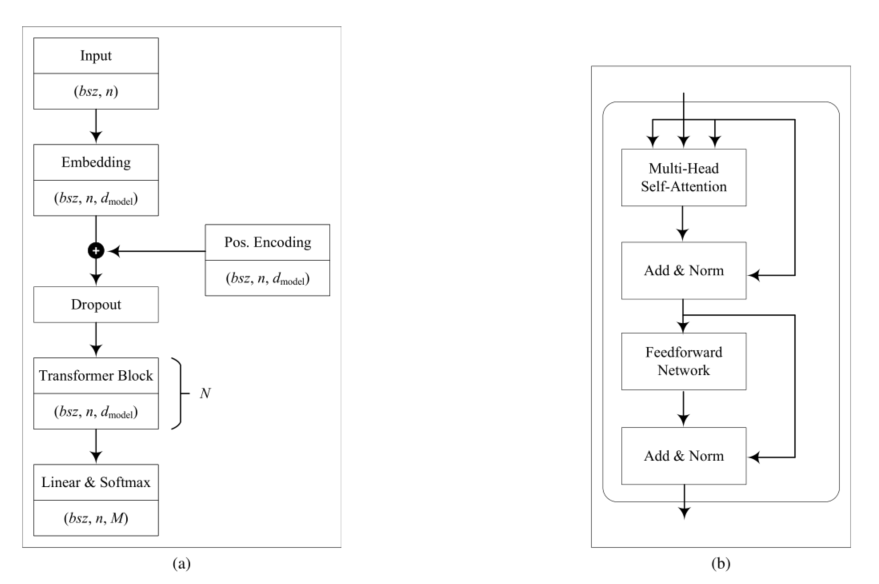
N表示Transformer的数量、 $d_{model}$ 表示嵌入长度、h表示Attention的数量, $d_{l}$ 表示Q,K,V的向量维度。
M表示词汇的数量,这里可以理解为事件的数量,n为单个流程的长度,bsz表示流程的数量,单次样本数量。
Pos.Encoding 位置编码标记
知识补充
神经网络中Epoch、Iteration、Batchsize相关理解和说明_Microstrong-CSDN博客_epoch
epoch:中文翻译为时期。
一个时期=所有训练样本的一个正向传递和一个反向传递。
举个例子,训练集有1000个样本,batchsize=10,那么:
训练完整个样本集需要:
100次iteration,1次epoch。
理解辅助:
这块主要和Transformer论文中的Shared-Weight Embeddings and Softmax这一部分一样
与其他序列转导模型类似,使用可学习的 Embeddings 将 input tokens and output tokens 转换为维度 的向量【序列转序列转为d(model)维度的向量】。通过线性变换和 softmax 函数将解码器的输出向量转换为预测的 token 概率。在 Transformer 模型中,两个嵌入层和 pre-softmax 线性变换之间共享相同的权重矩阵,在 Embeddings 层中,将权重乘以 . 这些都是当前主流的操作。
- 通过被一个正态分布初始权值的可训练查找矩阵构成的嵌入层将输入映射到一个 $d_{model}$ 维度的特征空间【①使用embedding将输入转化为 $d_{model}$ 维度的向量】,同时pre-softmax函数在transformer中使用相同的查找矩阵。
- 由于Transformer不对顺序有预测效果,所以将位置编码加入到嵌入向量中【与第一个方法类似结合sin,cos】
- 通过交叉熵和标签滑动来进行拟合结果和消除过拟合
- 最后作者提到注意计算结果在内部缓存并复用的问题,主要在担心内存溢出,但是实验缓冲所需的空间可忽略不计。
知识补充
label smoothing(标签平滑):正则化策略,为了防止过拟合,加入噪声
label smoothing(标签平滑)学习笔记 - 知乎
交叉熵即预测值与真实值之间的差值,越少越精准。
损失函数之交叉熵(一般用于分类问题) | 吾辈之人,自当自强不息!
知识补充: 模型理解
碎碎念:Transformer的细枝末节 - 知乎
Transformer理论源码细节详解 - 知乎
Transformer论文详解,论文完整翻译(七) | 码农家园
Transformer & Self-Attention (多头) 自注意力编码 | Fly Me to the Moon
结果验证
作者使用了前面提到的BPI2013和DATSET,每个数据集分为三个部分:培训,验证和测试。对于BPI2013的数据集,作者选的的训练、验证、测试集之间比例80%,10%,10%。DATSET则是96%,2%,2%。
BPI2013用了30000个训练模型,DATSET使用了一百万个,一个epoch为1000个。
- BPI2013
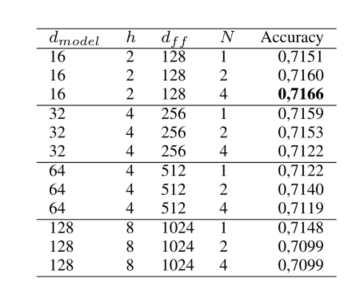
展示了四种超参数的配置 $d_{model}$ 为嵌入长度,h为Attention数量, $d_{ff}$ 规定了点式前馈神经网络的内部第一层输出节点, 为前反馈网络中的参数。
分析,在最小超参数的配置中,当结合四层Transformer后精确度达到最高。同时随着配置的增加,训练的效果却下降了,这里可能是设置超参数过大,欠拟合。

【4】”Comprehensible predictive models for business processes” 2016
【11】“Predicting process behaviour using deep learning”2016
【13】“A multi-stage deep learning approach for business process event prediction”2017
实验表明,我们的注意力竞争方法通常适用于过程事件预测的任务,并且可以与现有技术相当执行。
- DATSET
由于DATSET的数据集较大,这里直接使用较大的超参数,同时结合4和6层的transformer
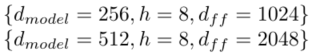
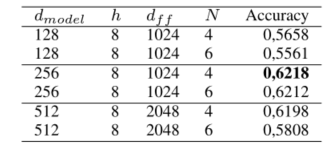
训练的时候将超过500的流程筛选出来,这些只占了数据集1%
分析,最高为0.6218。超参数较小的模型显着更糟糕,这表明它们无法完全模拟数据的复杂性。但是没有以前的数据进行对比,作者使用LSTM基本模型使用相同的超参数【256,N=4】进行对比。

证明了所提出的基于关注力的模型比基于LSTM的模型更好。此外,根据LSTM训练时间是我们的两倍。 TODO 这显示了注意机制对于长跟踪长度的优势,它能够一次处理整个跟踪,而不是一次处理一个元素。
总结
本文,作者提出了基于注意力机制的业务流程预测模型,通过数据集验证,不仅在较小的数据集上(BPI2013)可以接近现有技术的精确度,同时在预测复杂的的数据集也可以达到良好的效果,同时训练时间更少。
提到对于复杂的模型处理的新的思路,对于流程轨迹进行分割,对于重复的事件进行预处理,缩短流程提升预测精度或者是仅部分学习预测。
 wechat
wechat alipay
alipay








