
基于LSTM神经网络的业务过程预测监控

摘要
本文研究了长-短期记忆(LSTM)神经网络作为一种预测模型。并证明LSTMs在预测运行案例的下一个事件及其时间戳方面优于现有的技术。
简介
作者提到他的目的是提出一个可以适用的框架。本文的研究点:
- LSTMs能否被用于广泛的流程预测,以及如何应用?
- 如何保障LSTM在不同数据中的准确度始终如一?
在不同预测内容中,作者适用了4个日志数据集进行验证比较。
相关技术
主要讲的是目前对于三种预测的技术,包括了,时间相关预测、事件结果的预测、正在执行事件的预测
背景
日志
- 数据集A
- 数据集A中所有序列 $A^{*}$
- 一个长度为n的序列 σ =< $a_{1}$ , $a_{2}$ , $a_{3}$ , …… , $a_{n}$ >,空序列为<>
- $σ_ { 1 } \cdot σ _ { 2 }$ 表示序列 $σ_{1}$ 与 $σ_{2}$ 的串联
- $h d ^ { k } ( o ) = ( a _ { 1 } , a _ { 2 } , \cdots , a _ { k } )$ 为前缀长度为k(0<k<n) 的序列 σ的前缀。 $t l ^ { k } ( o ) = ( a _ { k + 1 } \cdots , a _ { n } )$ 是它的后缀。
对于前缀后缀的一个栗子:
序列: $σ _ { 1 } = ( a , b , c , d , e )$
前缀长度为二的前缀: $h d ^ { 2 } ( σ _ { 1 } ) = ( a , b )$
后缀为: $t l ^ { 2 } ( σ _ { 1 } ) = ( c , d , e )$
- $\varepsilon$ 【伊普西隆】为所有事件集合,T为时域。
- $\pi _{ \tau }\in \varepsilon \rightarrow T$ 为事件分配事件戳
- $\pi _{ A }\in \varepsilon \rightarrow A$ 从事件集A种为一个流程分配活动
RNN和LSTM
Long Short Term Memory Networks | 吾辈之人,自当自强不息!
下一个活动和时间戳预测
介绍评估多种体系结构预测下一个事件和时间戳。
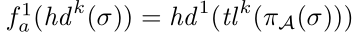
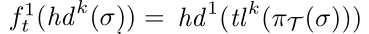
输入一个事件的前缀,然后预测下一个事件。
方法
知识补充
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
假设“花”的特征可能的取值为daffodil(水仙)、lily(百合)、rose(玫瑰)。one hot编码将其转换为三个特征:is_daffodil、is_lily、is_rose,这些特征都是二进制的。
什么是one hot编码?为什么要使用one hot编码? - 知乎
- 首先为LSTM构建特征向量矩阵,作为输入。
事件e=σ(i)的时间特征指的是在trace中的上一个时间和当前时间之间的时间。转换函数: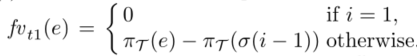
三种时间特征:fvt1表示事件的当前时间特征【与上一个时间的时间间隔】,同时也添加了包函一天时间的特征fvt2和包含一周的时间特征fvt3.这样当事件在工作日或者工作周结束的时候预测下一个活动的事件中时间间隔则会更长。
- LSTM可以通过fvt1学到不同节点的事件宇时间差的依赖关系。
- fvt2,fvt3的加入,是为处理有些有些事件超出了工作日的特殊情况,因为传统的日志处理中只记录工作日中的。
- 对时间步长k【第k个事件的时间】的输出 $o _ { a } ^ { k }$ 进行one-hot编码。
异常情况
- 当在时间k为事件的结尾,既没有新的事件可以预测。
解决
- 当在时间k结束时,给输出的one-hot编码向量增加额外标记值1
设置第二个输出值 $o_{t}^{k}$ 为下一个时间间隔的 $fv_{t1}$ 值。当知道当前时间戳,就可以计算到下一个事件的时间戳。
使用Adam算法【梯度下降算法】进行神经网络权重优化
如何优化:
- 最小化基础事件one-hot编码和被预测的下一个事件的one-hot编码的交叉熵。
- 最小化事件和预测事件之间时间的平均误差(MAE)
模型的构建
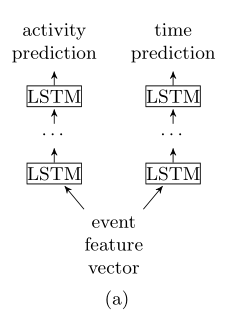
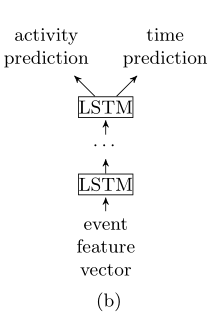
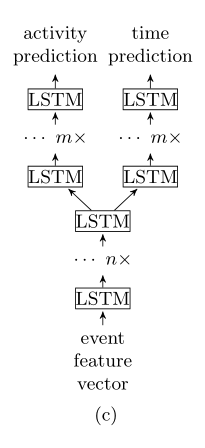
- 使用相同的数据特征,分别单独训练两个模型,一个是预测下一步事件,另一个是预测下一个时间戳,如图a
- 多任务学习可以在同一个神经网络结构学习到多个模型,例如图b,同一个LSTM神经网络结构学习输出两个模型。
- 混合模型
实现
- 使用的循环神经网络依赖库Keras构建项目
- 硬件是NVidia Tesla k80 GPU,每次epoch时间为15-90s。其中预测时间时间戳是以毫秒为单位的。
实验准备
评定标准
本文使用的MAE(平均绝对误差)来作为实验结果比较的参考。在实验效果评价这块,作者通过修改 van der Aalst提出的论文中用于预测剩余时间的模型来作为baseline。
实验准备
使用两个数据集进行预测下一个活动和时间戳。其中2/3的数据用于训练模型,1/3的用于预测。
这里数据中长度为2的序列进行 $2 \leq k \lt | o |$ 预测,长度小于2则不对其预测。
数据集
- 帮助中心数据集
来自于意大利软件公司的票务管理系统,主要包括9中事件,一种事务流程。其中流程总共有3804条,事件有13710个。
2. BPI12子数据集W
此事件日志源自Business Process Intelligence Challenge(BPI’12)2,包含来自大型金融机构金融产品应用程序的数据。此流程由三个子流程组成:一个子流程跟踪应用程序的状态,一个子流程跟踪与应用程序关联的工作项的状态,第三个子流程跟踪报价的状态。在预测未来事件及其时间戳的上下文中,我们对自动执行的事件不感兴趣。因此,我们将评估范围缩小到工作项子流程,其中包含手动执行的事件。此外,我们过滤日志以仅保留complete类型的事件。
结果分析
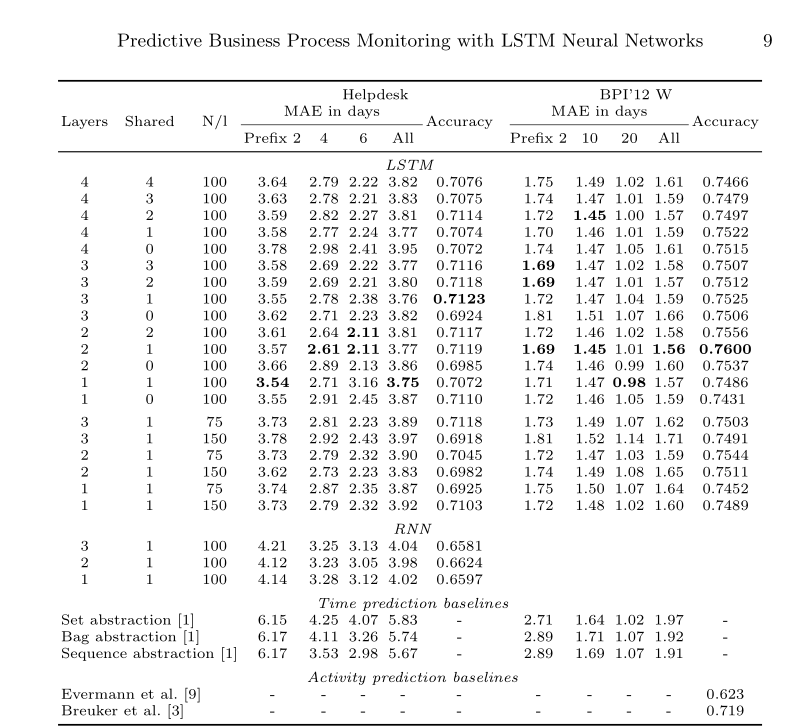
N表示神经元。MAE为当前配置不同前缀长度的性能。
表1显示了help desk和BPI’12w子流程日志上各种LSTM体系结构在MAE预测时间和预测下一事件准确性方面的性能。由于BPI12中的流程长度较长,所以前缀较长。
TODO 前缀不是很懂
分析:
- ALL LSTM体系结构在所有前缀上都优于baseline,同时分别比较LSTM模型和baseline模型,可以发现 短前缀的增益要比长前缀要好。
- 数据集helpdesk的预测准确度最好为71%;BPI’12 W数据集预测的最佳精度为76%,高于Breuker等人报告的71.9%的精度和Evermann等人报告的62.3%的精度。
- 预测精度最高的模型都为混合模型,尝试将每层的神经元数量减少到75个,对于只有一个共享层的架构,将其增加到150个,但发现这会导致两个任务的性能下降。可能有75个神经元导致模型欠拟合,而150个神经元导致模型过拟合。我们还在单层架构上对传统RNN进行了实验,发现它们在时间和活动预测方面都比LSTM差得多。
后缀预测
本章理解
区别于上一节,上一章是单个时间步长预测下一步,而本章是预测一个运行案例的整个延续。
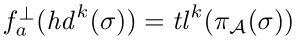
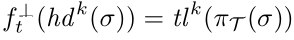
方法
通过迭代地预测下一个事件和时间戳,然后再次进行预测直至这个案例结束。这里用 $\perp$ 表示案例结尾。
迭代预测:
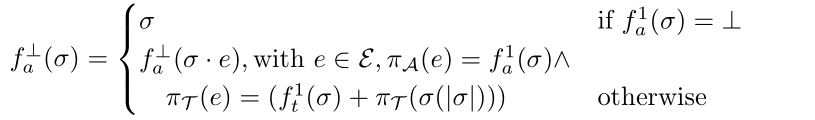
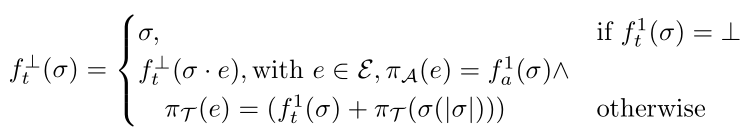
当当前事件为END,则不进行预测;否则将预测的结果输入到预测模块迭代预测。
准备
对于预测准确度的评价这里采用的是通过计算预测结果与实际结果的编辑距离来衡量。
知识补充:Levenshtein distance
字符串相似度算法(编辑距离算法 Levenshtein Distance) - ZYB - 博客园
问题:
当处理并发任务的时候,Levenshtein distance并不适用于计算。例如<a,b>为预测的下一个事件,但实际上为<b,a>,这种情况只是因为ab并发顺序导致的,实际上并无相关。但是Levenshtein distance结果为2,因为将预测序列转换为实际序列需要一次删除和一次插入操作。
解决
Damerau-Levenstein距离是一种更好地反映预测质量的评估度量,它为Levenshtein距离使用的操作集添加了交换操作。Damerau-Levenshtein距离将分配1的转换成本⟨a、 b⟩ 进入⟨b、 a⟩. 为了获得可变长度记录道的可比较结果,我们通过实际案例后缀长度和预测后缀长度的最大值对Damerau-Levenshtein距离进行归一化,归一化的Damerau-Levenshtein距离减1以获得Damerau-Levenshtein相似性(DLS)。
模型
采用的是双层架构,每层100个神经元的LSTM。
数据集
这是荷兰某市政当局环境许可程序的日志每宗个案涉及一份许可证申请。
该日志包含937个案例和381种事件类型的38944个事件。几乎每一种情况都遵循一个独特的路径,这使得后缀预测更具挑战性。
结果

Polato为baseline,no duplicates表示去掉案例中的重复事件,但是保留一个【案例结尾即使为重复事件也不去掉】。
观察可以发现所有数据集中的LSTM预测结果都要好于baseline。在BPI12数据集种很多案例中的事件会重复的出现,这就会导致预测的后缀长于真实案例,因此删除了BPI12中重复的事件并重新进行评估。
总结
- 利用LSTM神经网络预测运行案例的下一个活动及其时间戳的技术。表明,这种技术在现实数据集上优于现有的基线。此外,我们发现通过单一模型(多任务学习)预测下一个活动及其时间戳比使用单独的模型进行预测具有更高的准确性。
- 提出了一个运行种的案例整个延续的预测和预测剩余的周期时间的解决方案。
- 发现了LSTM模型的局限性,**即在一个案例种某些事件多次重复出现时,导致后缀过长,性能就会很低**。
 wechat
wechat alipay
alipay








