
Long Short Term Memory Networks
人人都能看懂的LSTM - 知乎
RNN、LSTM、GRU基础原理篇 - 知乎
机器学习:深入理解 LSTM 网络 (一)_Matrix-11-CSDN博客_lstm 机器学习
中文分词、词性标注、命名实体识别、机器翻译、语音识别都属于序列挖掘的范畴。序列挖掘的特点就是某一步的输出不仅依赖于这一步的输入,还依赖于其他步的输入或输出。在序列挖掘领域传统的机器学习方法有HMM(Hidden Markov Model,隐马尔可夫模型)和CRF(Conditional Random Field,条件随机场),近年来流行深度学习算法RNN(Recurrent Neural Networks,循环神经网络)。
RNN
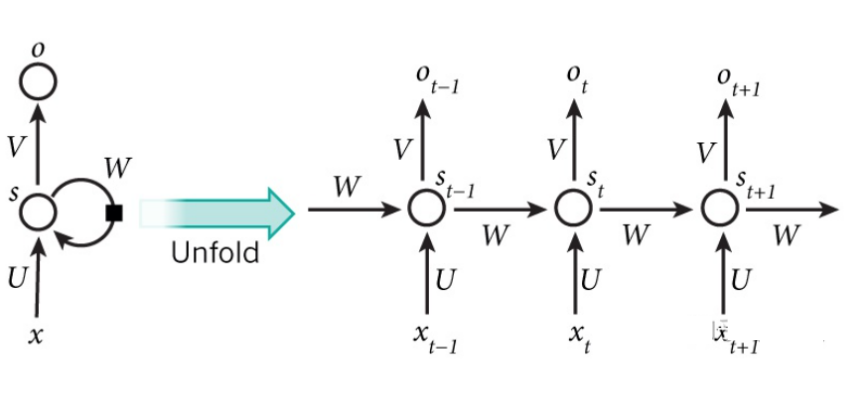
比如一个句子中有5个词,要给这5个词标注词性,那相应的RNN就是个5层的神经网络,每一层的输入是一个词,每一层的输出是这个词的词性。
RNN的变体
双向RNN
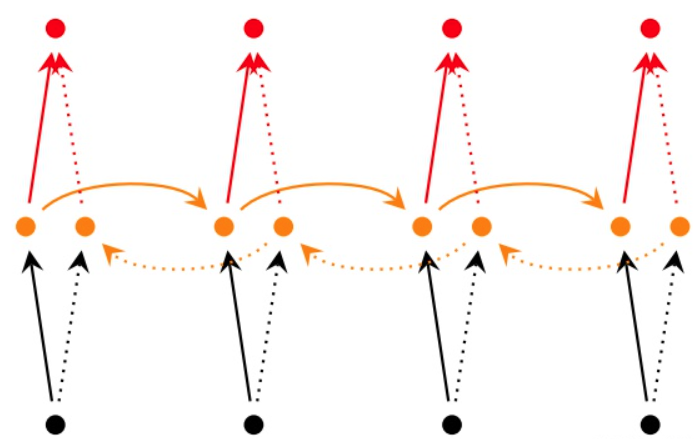
双向RNN认为otot不仅依赖于序列之前的元素,也跟tt之后的元素有关,这在序列挖掘中也是很常见的事实。
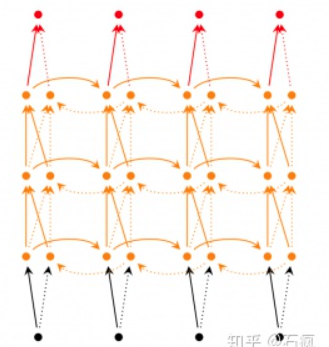
深层双向RNN
在双向RNN的基础上,每一步由原来的一个隐藏层变成了多个隐藏层。
LSTM
前文提到,由于梯度消失/梯度爆炸的问题传统RNN在实际中很难处理长期依赖,而LSTM(Long Short Term Memory)则绕开了这些问题依然可以从语料中学习到长期依赖关系。
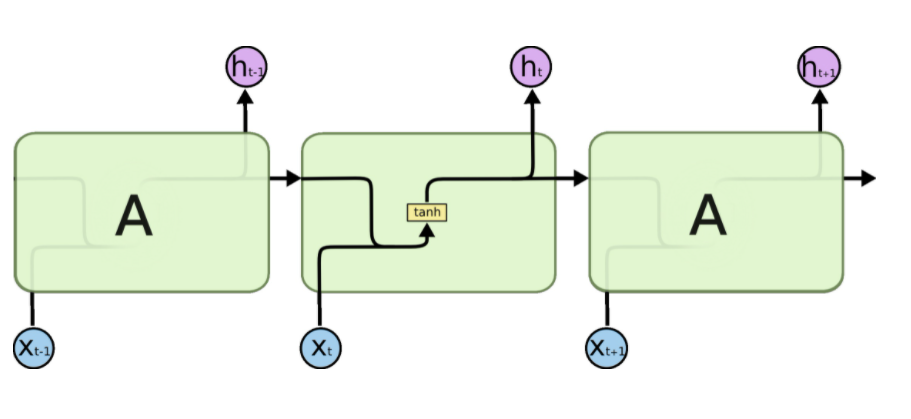
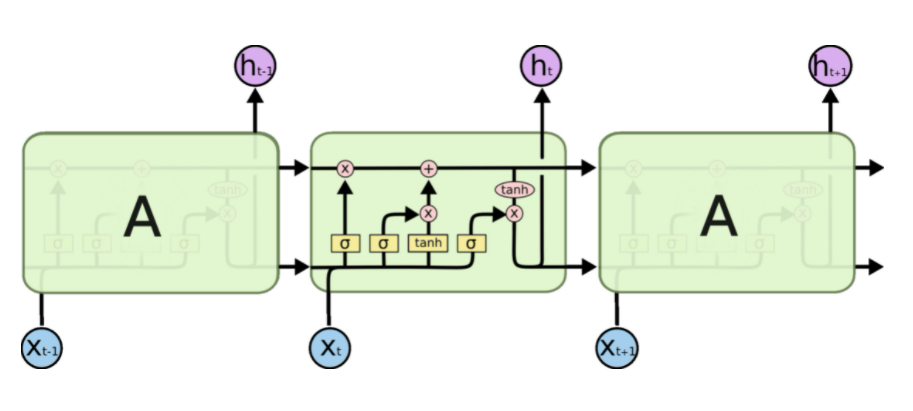
解释LSTM模块:
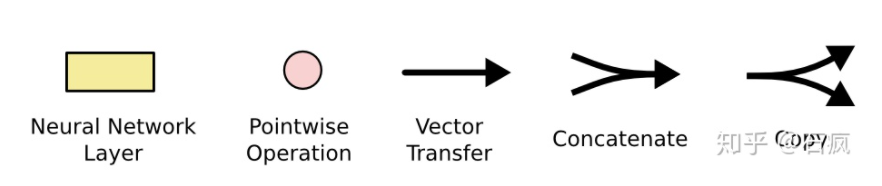
- 粉色的圆圈表示一个二目运算。
- 两个箭头汇合成一个箭头表示2个向量首尾相连拼接在一起。
- 一个箭头分叉成2个箭头表示一个数据被复制成2份,分发到不同的地方去。
LSTM的关键是细胞状态C,一条水平线贯穿于图形的上方,这条线上只有些少量的线性操作,信息在上面流传很容易保持。
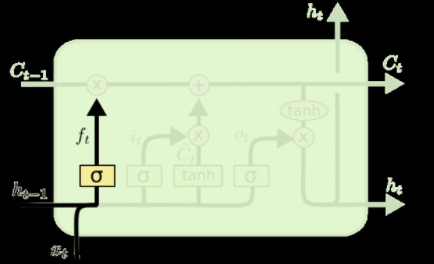
- 忘记层,决定细胞状态中丢弃什么信息。把ht−1和xt拼接起来,传给一个sigmoid函数,该函数输出0到1之间的值,这个值乘到细胞状态Ct−1上去。sigmoid函数的输出值直接决定了状态信息保留多少。比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
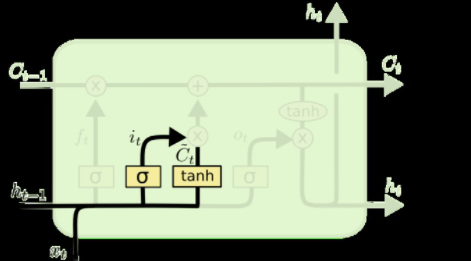
2. 上一步的细胞状态Ct−1已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?这里又包含2层:一个tanh层用来产生更新值的候选项C~t,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;还有一个sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
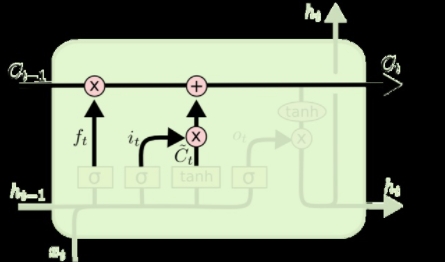
3. 现在可以让旧的细胞状态Ct−1与ft(f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分it∗C~t(i是input输入门的意思),这就生成了新的细胞状态Ct
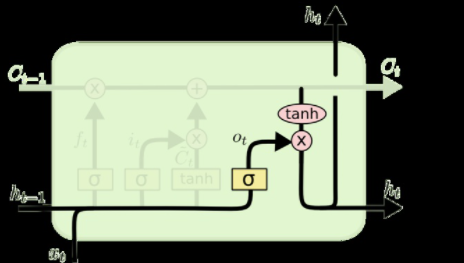
4. 最后该决定输出什么了。输出值跟细胞状态有关,把Ct输给一个tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
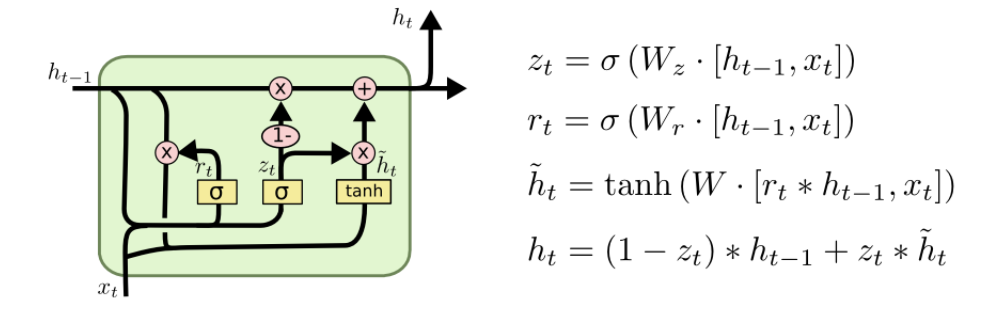
GRU
GRU(Gated Recurrent Unit)是LSTM最流行的一个变体,比LSTM模型要简单。没有了存储单元
总结
RNN 结构的一个吸引人之处在于其可以利用之前的输入信息。但是一个关键的需要解决的问题是当前的信息与之前的信息的关联度有长有短。
LSTM的内部结构。通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。、
但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
 wechat
wechat alipay
alipay








