
业务流程的LSTM精准模型
摘要
使用LSTM模型对事件下一步,时间戳和调用的资源进行预测。
简介
本文主要是对于前人提出在LSTM中利用近似前缀预测—基于LSTM神经网络的业务过程预测监控 | 吾辈之人,自当自强不息!的缺陷的改进,缺陷:
- 无法处理数字变量
- 不能生成带有时间戳的时间序列
- 后续有文章提出通过one-hot编码来对事件进行分类,而不是使用嵌入维度来实现的,这样随着事件类型的增加,精度就会极度下降。
知识补充
后处理:在模型训练后,人为的修改模型结果使之预测结果更加符合真实情况。
数据挖掘之_后处理_谢彦的技术博客-CSDN博客_数据后处理
- 解决:
本文通过提出用于建立新的预处理和后处理方法和架构以及使用LSTM神经网络的事件日志的生成模型来解决上述方法的局限性。 - 具体地说,本文提出了一种方法去学习模型,该方法可以生成由三组(事件类型、角色、时间戳)组成的轨迹(或从给定前缀开始的轨迹的后缀)。提出的方法结合了Tax等人[13]和Evermann等人[2]的优点,通过使用嵌入维度,同时支持事件日志中的分类属性和数字属性。本文考虑了神经网络中共享层和特有层的不同组合所对应的三种体系结构。
评估:
- 第一种方法比较了与不同体系结构、预处理和后处理选择相对应的所提出方法的备选实例。该评估的目的是根据获取到的日志的特征,得出关于哪些设计选择更可取的指南。
- 比较提出方法在上面三条约束的表现。
技术背景
LSTM 当前的进展
- 使用LSTM对于事件类型较少的序列进行迭代循环预测,使用的是one-hot编码将事件类型,事件戳映射到向量特征向量,并使用事件发生的时间特征对其进行补充。缺点是当事件类型较多的时候,该方法效果会变差。
- 该模型由共享LSTM层构成,其中包括一个专门用于预测事件的LSTM和一个预测事件的LSTM

- 使用嵌入维度的LSTMs,可以减少输入长度和增加新的特征。缺点是依旧无法处理数值变量,所以也不能预测时间戳。优点是可以处理大量事件类型。
- 使用两层LSTMs隐藏层。

- 提出基于RNN的模型MM-Pred来预测下一步事件和流程后续。缺点是无法处理数值变量,所以也不能预测时间戳。
- 这种方法同时使用控制流信息(事件类型)和案例数据(事件属性)。
- 该结构由编码器、调制器和解码器组成。
- 编码器和解码器使用LSTM网络将每个事件的属性转换为隐藏表示或从隐藏表示转换为隐藏表示。
- 调制器组件求出可变长度序列比对权重向量,其中每个权重表示用于预测未来事件和属性的属性的相关性。

- 使用多阶段深度学习的方法来预测下一个事件。缺点是无法处理数值变量,所以也不能预测时间戳。
- 首先是将每个事件映射到特征向量
- 下一步使用transformations降低输入维度,通常有,通过提取n-gram、使用hash、将输入通过两个自动编码层等方法
- 将转化后的输入传给负责预测的前馈神经网络
- 作者提出一种基于GRU的神经网络架构BINet,用于业务流程执行中的实时异常检测。该架构用于预测下一个事件及属性。
- 该方法旨在为跟踪中的每个事件分配一个似然分数,然后用于检测异常。这种方法表明,过程行为的生成模型也可用于异常检测。
- 作者比较几种真实数据集在MMs,all-k MMs以及基于自动机的模型中预测下一步的准确性和性能。
- 结果表明,AKOM模型具有最高的精度(在某些情况下优于RNN体系结构),而基于自动机的模型具有较高的可解释性。

实现
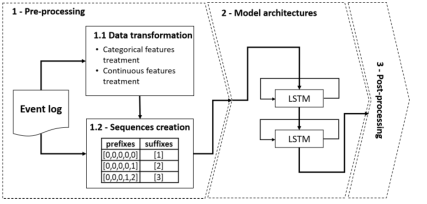
预处理阶段
Data transformation
根据属性性质(分类或连续)进行特定预处理。
分类:
处理数据:将事件和资源作为类别属性,使用嵌入维度。
向训练网络提供属性之间关联的正面和负面示例,使网络能够识别和定位具有相似特征的近似属性。根据NLP社区4中使用的一项通用建议,嵌入维度的数量被确定为类别数量的第四根,以避免它们之间可能发生冲突。生成的值作为不可训练的参数导出并在所有实验中重用,这样就不会增加模型的复杂性
连续:
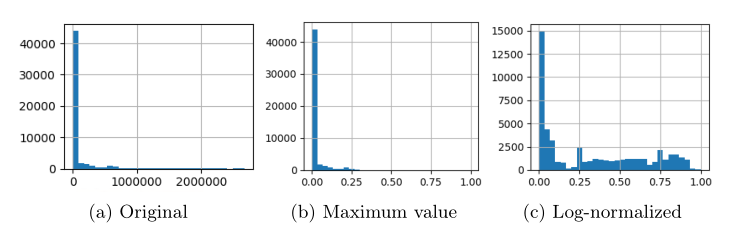
对数据进行归一化,以供预测模型解释。这里处理的事件之间的相对时间,问题在于不同日志,相对时间可能具有很大的可变性。 这种高可变性可以隐藏有关过程行为的有用信息,例如时间瓶颈或异常行为,如果不小心执行属性缩放,则可以隐藏这些信息。
寻求一种合适的缩放方法。
Sequences creation
提取每个事件日志跟踪的固定大小的n-gram,以创建输入序列和预期事件来训练预测网络。
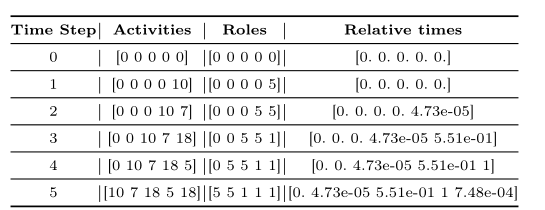
role表示的是事件与资源的关联
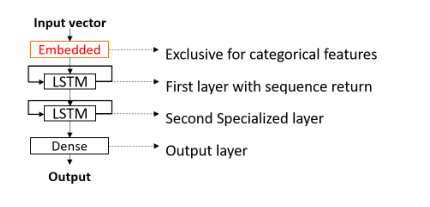
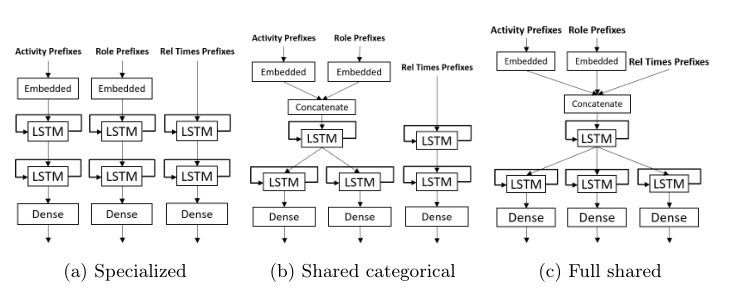
Model Structure Definition Phase
Post-processing Phase
从零前缀开始生成业务流程的完整跟踪中,传统使用的是arg max,直接根据下一个事件的最大概率来跟踪,但是这就会所有追踪的事件都倾向于概率最大值,对于低概率发生的事件无法追踪。这里作者使用的是arg max和随机选择的参数作为下一个事件的选择。
我觉得应该使用softmax
评估
本节描述了两个实验评估。第一个实验比较了三种架构在前处理和后处理选择方面的不同实例。第二个实验将提出的方法与技术背景中其它论文中的下一个事件、后缀和剩余时间预测任务的三条基线进行比较
Data Set
在本实验中,使用了九个来自不同领域、具有不同特征的真实事件日志
- Helpdesk5事件日志包含来自意大利软件公司helpdesk票务管理过程的记录
- BPI 20126 中的两个事件日志与来自德国金融机构的贷款申请流程相关。 这个过程由三个子过程组成,我们从中使用了 W 子过程,以便与”下一个元素预测序列建模方法的跨学科比较”进行比较 。
- BPI 20137中的事件日志与沃尔沃的IT事件和问题管理有关。我们使用完整的案例学习生成模型
- BPI 20158中的五个事件日志包含五个荷兰城市在四年期间提供的建筑许可证申请数据。原始事件日志分为五个部分(每个市政局一个)。所有事件日志都在子流程级别指定,包括345多个活动。因此,按照”Diagnostics of building per-mit application process in dutch municipalities”中所述的步骤对其进行预处理,以便在阶段级别进行管理
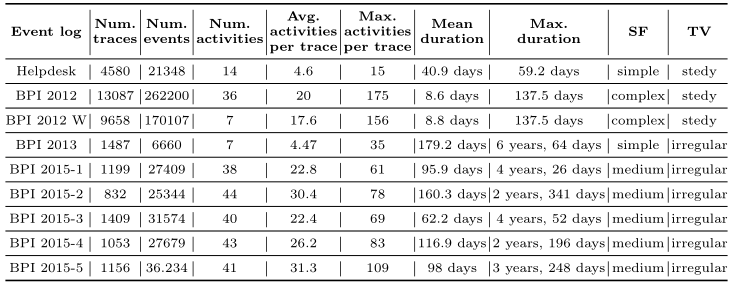
- SF指根据其在记录道数量、事件、活动和序列长度方面的组成分为简单、中等和复杂。
- TV指据每个事件日志的平均持续时间和最大持续时间之间的关系,将时间变异性(TV)分为稳定或可变
Experimental setup
目的:
使用 LSTM 模型从大小为0的前缀开始跟踪生成完整的事件日志,然后将生成的跟踪与原始日志中的流程进行比较。
方法:使用两个指标来评估生成的事件日志的相似性。
- Demerau-Levinstain(DL)算法根据一个字符串与另一个字符串相等所需的版本数测量序列之间的距离。该算法在每次执行插入、删除、替换和转置等操作时都进行惩罚。因此,我们使用其倒数来衡量生成的活动或角色序列与实际事件日志中观察到的序列之间的相似性。然后,较高的值意味着序列之间的相似性较高。
- 平均绝对误差(MAE)度量用于测量预测时间戳的误差。通过取观测值和预测值之间距离的绝对值,然后计算这些震级的平均值来计算该测量值。我们使用该度量来评估每对(生成轨迹、地面真值轨迹)的生成相对时间和观测时间之间的距离。
使用交叉验证,将事件日志分为两部分:70%用于培训,30%用于验证。第一个折叠被用作训练2000个模型的输入(每个事件日志大约220个模型)。
这平均220个模型配置了不同的预处理技术和体系结构。配置值是从972个组合的完整搜索空间中随机选择的。然后,使用每个经过培训的模型生成完整事件的新事件日志(参见第3节中描述的选择下一个活动的技术)。生成了每个配置的15个日志,并对其结果进行了平均。评估了32000多个生成的事件日志。
Results and Interpretation.
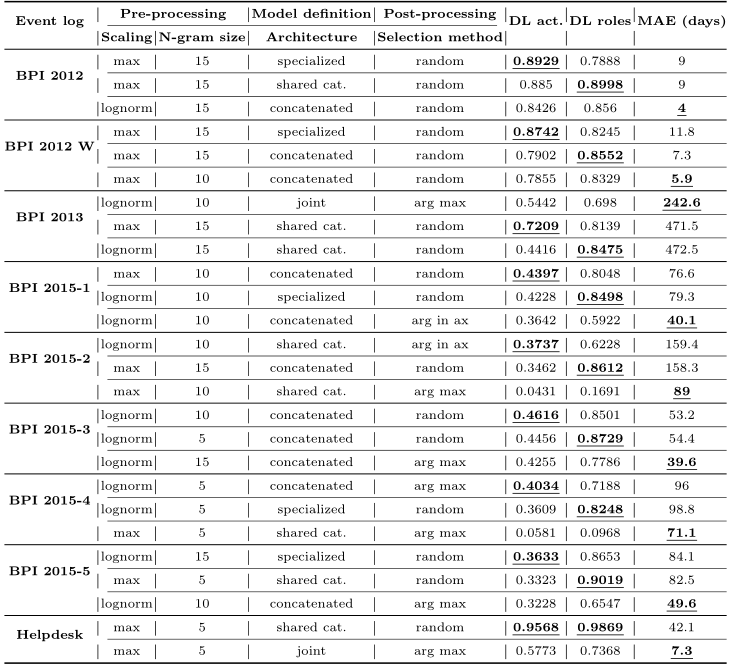
- MAE列对应于预测记录道周期时间的平均绝对误差
结果表明,使用这种方法可以训练学习并可靠地再现原始日志的观察行为模式的模型。此外,研究结果表明,对于LSTM模型来说, 学习词汇量较大 的序列比学习较长的序列更困难。要了解这些模式,需要更多的示例,如BPI2012和BPI2015的结果所示。这两个日志都有30多个活动,但在跟踪数量上有很大差异(见表2)。BPI2012的高度相似性还表明,使用嵌入维度处理大量事件类型可以改善结果,只要示例数量足以学习底层模式。
针对本实验中评估的模型结构构件,我们按照预处理、模型结构和超参数选择以及预测等阶段对其进行分析,以构建生成模型。
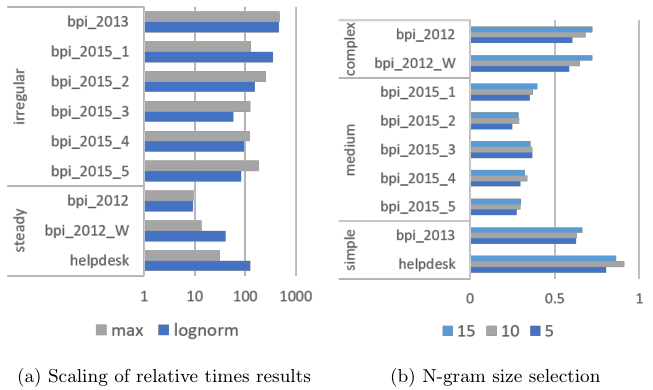
这里主要比较的是对于相对时间缩放方式,和进行缩放的作用。
- a 说明了如何使用最大值作为缩放技术,具有很小时间变化的日志呈现更好的结果。相比之下,具有不规则结构的日志使用对数归一化具有较低的 MAE【横坐标】。
- b 展示了使用不同大小的 n-gram 时的 DL 相似性结果,与事件日志的结构有关。 我们可以观察到,使用更长的n-grams对于trace更长的日志有更好的结果,呈现出稳定的增长趋势。 相比之下,中、简单结构的事件日志趋势不明显。 因此,应将长 n-gram 的使用保留给具有很长跟踪的日志。**这里体现的是n-gram size对于预测结果的作用,只有复杂的日志呈现良好的正相关。**
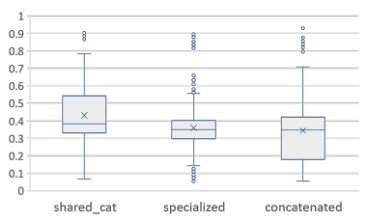
关于模型结构定义阶段,图说明连接结构的总体相似度最低。相比之下,仅在分类属性之间共享信息的模型体系结构具有中等最佳性能。然而,它与专门的体系结构并不遥远,尽管它的分布范围更广。这意味着在不同性质的属性之间共享信息会在网络正在处理的模式中产生噪声,从而阻碍学习过程。
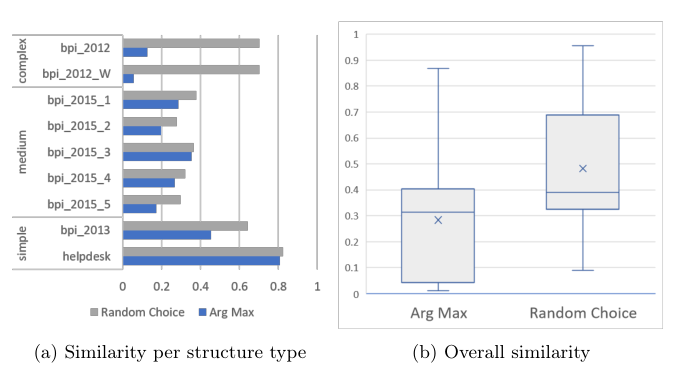
关于预测阶段,图显示了随机选择在所有事件日志中如何优于arg max。这种行为在具有较长和复杂跟踪的事件日志中更为明显。结果表明,无论事件日志结构如何,随机选择都是评估学习过程的可取方法。
Comparison Against Baselines
Experimental setup
目的:
评估我们的方法在预测下一个事件、剩余事件序列(即后缀)和剩余时间(对于不同长度的跟踪前缀)方面的相对性能。
- next event prediction — 为每个模型提供长度增加的跟踪前缀,从 1 到每个跟踪的长度。 对于每个前缀,我们预测下一个事件并测量准确性(正确预测的百分比)。
- suffix and remaining time prediction — 为模型提供了长度增加的前缀,直到案件结束。
baselines:
- next event and suffix prediction
- Predictive business process monitoring with LSTM neural networks
- Predicting process behaviour using deep learning
- A deep predictive model for multi-attribute event sequence
- remaining time prediction
- Predictive business process monitoring with LSTM neural networks【Helpdesk, BPI2012W and BPI2012 event logs】
Results and Interpretation
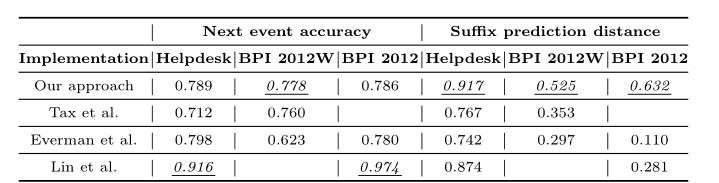
这些结果表明,分类属性的维度控制所采用的措施,使我们的方法即使在长序列中也能获得始终如一的良好性能。
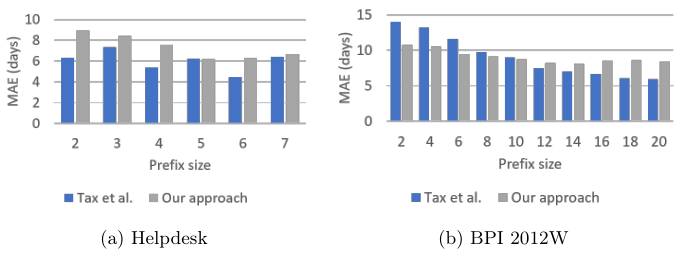
图10显示了剩余循环时间预测的MAE。尽管我们的技术目标不是预测剩余时间,但与Tax等人相比,它在这项任务中实现了类似的性能——在一个日志中略逊于它,在另一个日志中略逊于它的长前缀。
结论
优
- 评估表明,使用更长的n-gram可获得更高的精度
- 对数归一化是适用于高可变性测井的缩放方法,与总是选择最有可能的下一个事件相比,使用LSTM产生的概率随机选择下一个事件可导致更广泛的记录道和更高的精度。论文还表明,该方法在预测剩余事件序列及其从给定跟踪前缀开始的时间戳方面优于现有的基于LSTM的方法
作者预计,所提出的方法可以作为业务流程模拟的工具。实际上,从本质上讲,流程模拟器是一种通用模型,它生成由事件类型、资源和时间戳组成的跟踪集,并从中计算性能度量,如等待时间、循环时间和资源利用率。虽然流程模拟器依赖于可解释的流程模型(例如BPMN模型),但原则上可以使用能够生成事件跟踪的任何模型来模拟流程,其中每个事件都由事件类型(活动标签)、时间戳和资源组成。使用LSTM网络进行流程模拟的一个关键挑战是如何捕获“假设”场景(例如,删除任务或删除资源的效果)。
future
计划应用技术,使用”An eye into the future: Leveraging a-priori knowledge in predictive business process monitoring.”中的约束,从LSTM模型生成事件序列
 wechat
wechat alipay
alipay








